
What is Tessel 2?
Tessel 2 is a Wi-Fi-enabled development board programmable in JavaScript with Node.js. The first units shipped this month. There is a lot that I like about Tessel 2:
- It is high-level. JavaScript and Node.js greatly lower the barrier of entry since there are so many developers familiar with these technologies.[1]
- It works out of the box. Take the device, plug it, push some JavaScript, and it does its magic! There is no need to install your own Linux distribution or additional software.
- It is autonomous. Thanks to its powerful hardware[2], built-in Wi-Fi and Node.js, it runs independently from other computers or even cables (except for power).
- It is open. The Tessel 2 software and hardware are open source. In fact, Tessel is not even a company but “just a collection of people who find it worthwhile to spend [their] time building towards the Tessel Project mission.”[3]
It short Tessel 2 seems perfect for playing with IoT!
From JavaScript to Scala
As soon as I got my Tessel 2, I followed the tutorial to get a basic hang of it, and that went quite smoothly.
But my plan all along had been to use Scala on Tessel 2. You might know Scala primarily as a server-side language running on the Java VM. But Scala also compiles to JavaScript thanks to Scala.js, and it does it spectacularly well.
So I set to do something simple like toggling relays, but in Scala instead of JavaScript. Here are the rough steps:
- setup a Scala.js sbt project
- write an app calling the Tessel LED and relay module APIs
- run
sbt fullOptJsto compile the Scala code to optimized JavaScript - run
t2 run target/scala-2.11/tessel-scala-opt.jsto deploy the resulting JavaScript to Tessel
After I figured out a couple of tweaks (scalaJSOutputWrapper and .tesselinclude), it just worked! Here is the code:
object Demo extends js.JSApp {
def main(): Unit = {
println(s"starting with node version ${g.process.version}")
val tessel = g.require("tessel")
val relayMono = g.require("relay-mono")
val relay = relayMono.use(tessel.port.A)
relay.on("ready", () ⇒ {
println("Relay ready!")
js.timers.setInterval(2.seconds) {
relay.toggle(1)
}
js.timers.setInterval(1.seconds) {
relay.toggle(2)
}
})
relay.on("latch", (channel: Int, value: Boolean) ⇒ {
println(s"Latch on relay channel $channel switched to $value")
if (value)
tessel.led.selectDynamic((channel + 1).toString).on()
else
tessel.led.selectDynamic((channel + 1).toString).off()
})
}
}Notice how I can call Tessel APIs from Scala without much ado.[4] When used this way, Scala.js works like JavaScript: it’s all dynamic.[5]
Types and facades
But a major reason to use Scala instead of JavaScript is to get help from types. So after that initial attempt I wrote some minimal facades[6] for the Tessel and Node APIs I needed. Facades expose typed APIs to Scala, which allows the compiler to check that you are calling the APIs properly, and also gives your text editor a chance to provide autocompletion and suggestions. You can see this in action in IntelliJ:
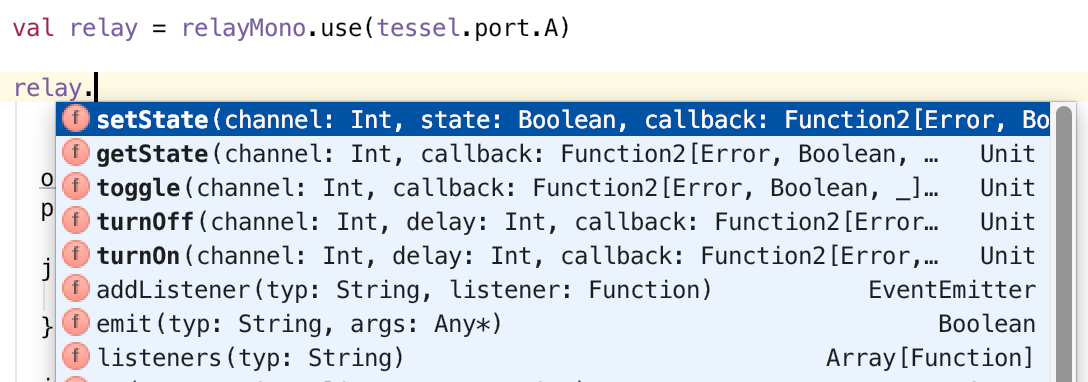
Here are the minimal facades I have so far:
Along the way I realized that working on facades is also a great way to learn APIs in depth! This is the resulting code (which you can find on github):
object Demo extends js.JSApp {
def main(): Unit = {
println(s"starting with node version ${g.process.version}")
val tessel = Tessel()
val relayMono = RelayMono()
val relay = relayMono.use(tessel.port.A)
relay.onReady {
println("Relay ready!")
js.timers.setInterval(2.seconds) {
relay.toggle(1)
}
js.timers.setInterval(1.seconds) {
relay.toggle(2)
}
}
relay.onLatch { (channel, value) ⇒
println(s"Latch on relay channel $channel switched to $value")
if (value)
tessel.led(channel + 1).on()
else
tessel.led(channel + 1).off()
}
}
}
As you can see, it’s not very different from the dynamic example, except that I now get help from the editor and compiler.
Why do this, again?
Now you might argue that in both cases the code looks more or less like JavaScript, so why go through the trouble?
It’s true that, superficially, JavaScript and Scala look very similar in these examples. But underneath there is Scala’s type system at work, and this is for me the main reason to want to use that language.
This said, there is more, such as:
- Immutability by default. I like this because it helps reduce errors and works great with functional programming idioms.
- Collections. Scala has a very complete collection library, including immutable collections (but you can also use mutable collections).
- Functional programming. Scala was designed for functional from the get go and has some pretty neat functional programming third-party libraries too.
And I could go on with features like case classes, pattern matching and destructuring, for-comprehensions, and more. But I should also mention a few drawbacks of using Scala instead of JavaScript:
- Harder language. Scala is a super interesting language, but no matter how you look at it, it is a bigger beast than JavaScript.
- Executable size. Scala.js has an amazing optimizer which also strips the resulting JavaScript from pretty much any unused bit of code[7]. Still, you will likely have resulting files which are larger than what you would get by writing JavaScript by hand. So expect your app to yield uncompressed JavaScript files in the order of a few hundreds of KB (much smaller when compressed). Tessel doesn’t seem to have any issues with that so far, so it might not be a problem at all, but it’s worth keeping an eye on this as Tessel doesn’t have Gigabytes of RAM.
- Compilation step. There is a compilation and optimization step in addition to publishing the software to Tessel. For my very simple demo, this takes a couple of seconds only. For larger projects, the time will increase. Now this is very manageable thanks to sbt’s incremental compilation, and if you consider that pushing a project to Tessel can take several seconds anyway, I would say that right now it’s not an issue.
So who would want to program Tessel in Scala? Probably not everybody, but it’s a great option to have if you already know the language or are interested in learning it, especially if you are going to write large amounts of code.
What’s next?
I plan to continue playing with Tessel 2 and Scala. The next step is to try to do something fun (and maybe even useful) beyond blinking LEDs and relays!
-
This trend is definitely in the air. Read for example Why JavaScript is Good for Embedded Systems. ↩
-
Tessel 2 is fairly beefy compared to an Arduino board, for example: it features a 580 MHz CPU, built-in 802.11 b/g/n Wi-Fi, and 64 MB of RAM and 32 MB of Flash. You can add more storage via USB. ↩
-
From Code of Conduct/About the Tessel Project/How to Get Your Issue Fixed. It is all the more impressive that they managed to make and ship such cool hardware and software. ↩
-
There is one exception, which I had missed in an earlier version of this post, which is access to JavaScript arrays. If you only rely on dynamic calls, you have to cast to
js.Array[_], or use theselectDynamic()method. Here I chose the latter way. Things look nicer when you use facades. ↩ -
Under the hood, this is thanks to Scala’s
Dynamicsupport. ↩ -
Scala.js facades are lot like TypeScript declaration files. ↩
-
Also known as DCE for Dead Code Elimination. ↩




